
OpenRouter《AI 现状》报告深度解读
原文:https://openrouter.ai/state-of-ai
我来为你详细解读这份基于 100 万亿 token 真实使用数据的 LLM 行业研究报告。
📊 核心发现
1. 开源 vs 闭源模型格局
市场份额演变
- 闭源模型仍占主导(约70%),但开源模型已增长至 ~30% 的市场份额
- 中国开源模型从 2024 年底的 1.2% 暴涨至 2025 年某些周份的 30%
- 开源模型发布(如 DeepSeek V3、Llama 3.3、Qwen 3 Coder)后的使用量持续增长,证明是真实生产使用
开源模型 Top 玩家(按总 token 量排名)
- DeepSeek: 14.37T tokens
- Qwen: 5.59T
- Meta LLaMA: 3.96T
- Mistral AI: 2.92T
- Minimax: 1.26T
关键洞察:
- 开源生态从 DeepSeek 一家独大转向 多元化竞争,现在没有单一模型超过 25% 的开源份额
- 中等参数模型(15B-70B)崛起成为新的"最佳性价比",小模型(<15B)份额下降
2. 推理模型(Reasoning Models)的爆发式增长

- 2024 年 12 月 5 日 OpenAI 发布 o1 标志着从"单次生成"到"多步推理"的范式转变
- 推理模型现在占所有 token 使用量的 超过 50%
- Top 推理模型:xAI Grok Code Fast 1、Gemini 2.5 Pro、Gemini 2.5 Flash
3. Agent 推理(Agentic Inference)兴起
四大趋势证据:
- 工具调用激增: 带工具调用的请求占比持续上升(排除 5 月异常峰值)
- Prompt 长度暴涨: 从 1.5K → 6K+ tokens(增长 4 倍),编程任务常超 20K tokens
- Completion 长度增长: 从 150 → 400 tokens(增长近 3 倍)
- 序列长度翻倍: 平均从 2K → 5.4K+ tokens
关键洞察: LLM 正从"文本生成器"转变为"分析引擎",用户更多是提供大量上下文(代码库、文档)来获取洞察,而非开放式创作。
4. 使用场景分类:出乎意料的发现
全局使用分布(所有模型)
- 编程(Programming): 从 11% → 50%+(增长最快)
- 角色扮演(Roleplay): 一直保持高位
- 翻译、通用问答、科学、健康等其他场景
开源模型使用分布
- 角色扮演: ~52%(占据半壁江山!)
- 编程: 第二大类
- 其他:翻译、通用知识等
震撼发现:
"角色扮演"使用量几乎与"编程"相当!这颠覆了"LLM 主要用于生产力"的假设。创意对话、故事创作、游戏场景的需求远超想象。
各提供商的使用特征
| 提供商 | 主要用途 | 特点 |
|---|---|---|
| Anthropic Claude | 编程+技术 (>80%) | 企业级代码助手定位 |
| Google Gemini | 多样化(翻译、科学、通用知识) | 通用信息引擎 |
| xAI Grok | 编程为主(>80%),11月后多元化 | 受免费推广影响 |
| OpenAI | 从科学(>50%) → 编程+技术(58%) | 转向开发者工作流 |
| DeepSeek | 角色扮演(>66%) | 消费者对话定位 |
| Qwen | 编程(40-60%) | 技术开发者工具 |
5. 地理分布:全球化加速
各大洲份额:
- 北美: 47.22%
- 亚洲: 28.61%(从 13% 暴涨!)
- 欧洲: 21.32%
Top 10 国家(按 token 量):
- 🇺🇸 美国 47.17%
- 🇸🇬 新加坡 9.21%
- 🇩🇪 德国 7.51%
- 🇨🇳 中国 6.01%
- 🇰🇷 韩国 2.88%
语言分布:
- 英语: 82.87%
- 简体中文: 4.95%
- 俄语: 2.47%
6. 用户留存:灰姑娘"玻璃鞋"效应
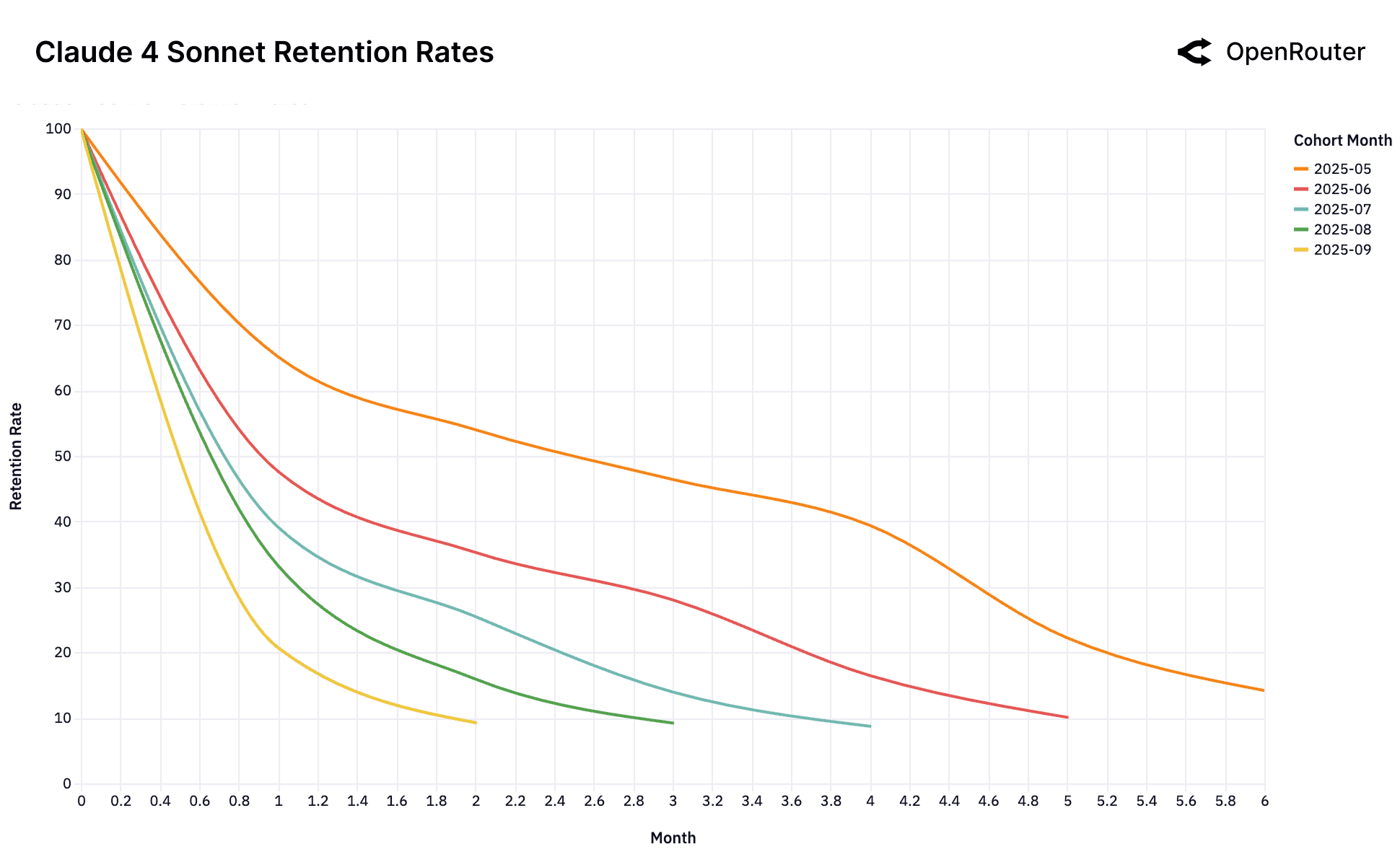
核心发现:
- 早期用户留存远高于后期用户(如 Gemini 2.5 Pro 和 Claude 4 Sonnet 的 2025 年 5-6 月队列在第 5 个月仍保持 ~40% 留存)
- GPT-4o Mini 的 2024 年 7 月队列形成"主导队列",所有后续队列均表现不佳
"玻璃鞋效应"理论:
当新模型首次解决某个高价值工作负载时,找到完美匹配的用户会形成强大的锁定效应——他们的系统、数据管道都围绕这个模型构建,切换成本极高。
反面案例:
- Gemini 2.0 Flash 和 Llama 4 Maverick 没有任何高留存队列,说明从未被视为"前沿"模型
- DeepSeek 出现"回旋镖效应":用户流失后又回归(在测试其他方案后确认 DeepSeek 更优)
7. 成本 vs 使用量动态
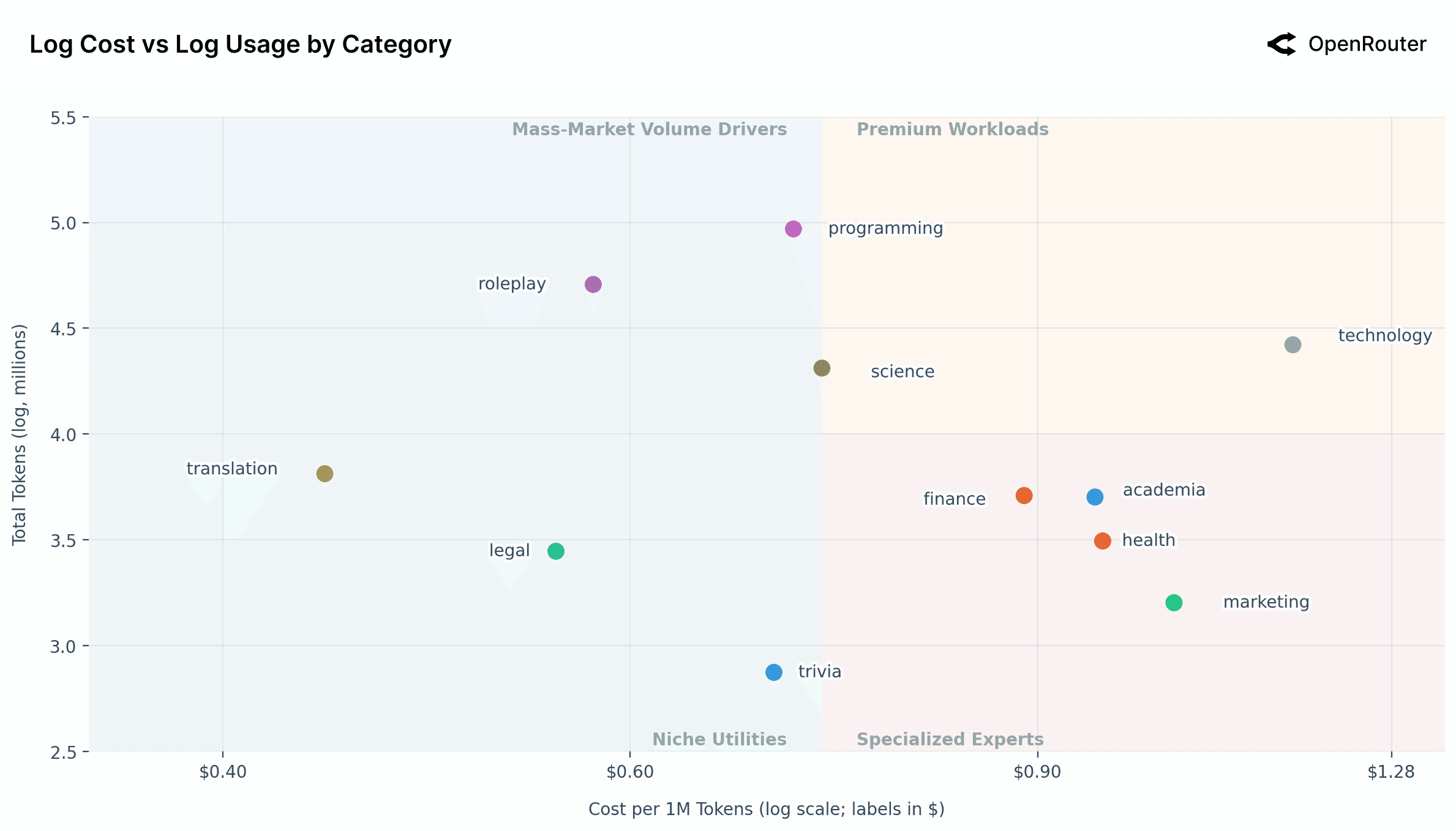
四大市场象限(以中位成本 $0.73/1M tokens 为分界):
| 象限 | 场景 | 特征 |
|---|---|---|
| 高价值高使用 | 科技、科学 | 专业工作负载,愿意为性能付费 |
| 大众量驱动 | 编程、角色扮演 | 最大用量,成本优化,开源优势明显 |
| 专家专用 | 金融、学术、健康、营销 | 低量高价,对准确性要求极高 |
| 利基实用 | 翻译、法律、琐事 | 低成本低量,已商品化 |
模型市场定位:
- 高效巨头: Gemini 2.0 Flash(0.147)、DeepSeek V3(0.394)
- 优质领导者: Claude 3.7/4 Sonnet(~$2),使用量仍很高
- 长尾模型: Qwen 2 7B(0.052)、IBM Granite(0.036)
- 优质专家: GPT-4(34)、GPT-5 Pro(35),用于最高要求任务
关键洞察:
- 整体需求价格弹性很低(价格降低 10% 仅增加使用量 0.5-0.7%)
- 但市场高度分层:企业关键任务不敏感,开发者管道高度敏感
- 有"杰文斯悖论"迹象:极便宜的模型被用于更多任务,总消耗反而增加
🎯 战略启示
对模型构建者:
- 持续迭代至关重要: 开源生态变化极快,停滞更新会迅速失去份额
- 首次解决问题 = 持久优势: "玻璃鞋时刻"决定长期留存,需抓住能力突破的窗口期
- 差异化仍有价值: 市场未商品化,质量/可靠性仍能支撑溢价
对应用开发者:
- 拥抱多模型策略: 没有单一模型主导,需根据任务选择最优方案
- Agent 工作流成为默认: 需支持长上下文、工具调用、有状态交互
- 不要忽视创意场景: 角色扮演等"非生产力"用途需求巨大
对基础设施提供商:
- 优化 Agent 推理: 不再是无状态请求,需管理长对话、执行轨迹、工具集成
- 成本优化关键: 缓存等技术使实际成本远低于标价,影响竞争力
- 全球化部署: 亚洲市场增长迅猛,需多语言/跨地区支持
💡 最震撼的反常识发现
- 角色扮演使用量 ≈ 编程使用量: LLM 不仅是生产力工具,更是情感陪伴/创意伙伴
- 开源模型占 1/3 市场: 远超大多数人预期,且在角色扮演场景已与闭源平分秋色
- 中国模型崛起: 从 1.2% → 30%,速度惊人
- 推理模型 > 50%: o1 发布一年内已成为主流
- 编程类 Prompt 长度 = 其他类 3-4 倍: 软件开发工作流复杂度远超想象
📚 方法论说明
- 数据来源: OpenRouter 平台 100T+ tokens 元数据(2024-2025)
- 分类方法: Google Cloud Natural Language API(GoogleTagClassifier)对 0.25% 样本分类
- 隐私保护: 仅分析元数据(token 数、时间戳、模型 ID 等),不接触实际对话内容
- 局限性:
- 仅反映 OpenRouter 平台(不包括企业内部部署)
- 地理位置基于账单地址(非真实位置)
- 分类数据始于 2025 年 5 月
这份报告是迄今为止最大规模的 LLM 真实使用行为研究,对理解 AI 行业现状和未来趋势具有重要参考价值。有任何具体问题想深入讨论吗?